PostgreSQL Is No Longer Just a Database
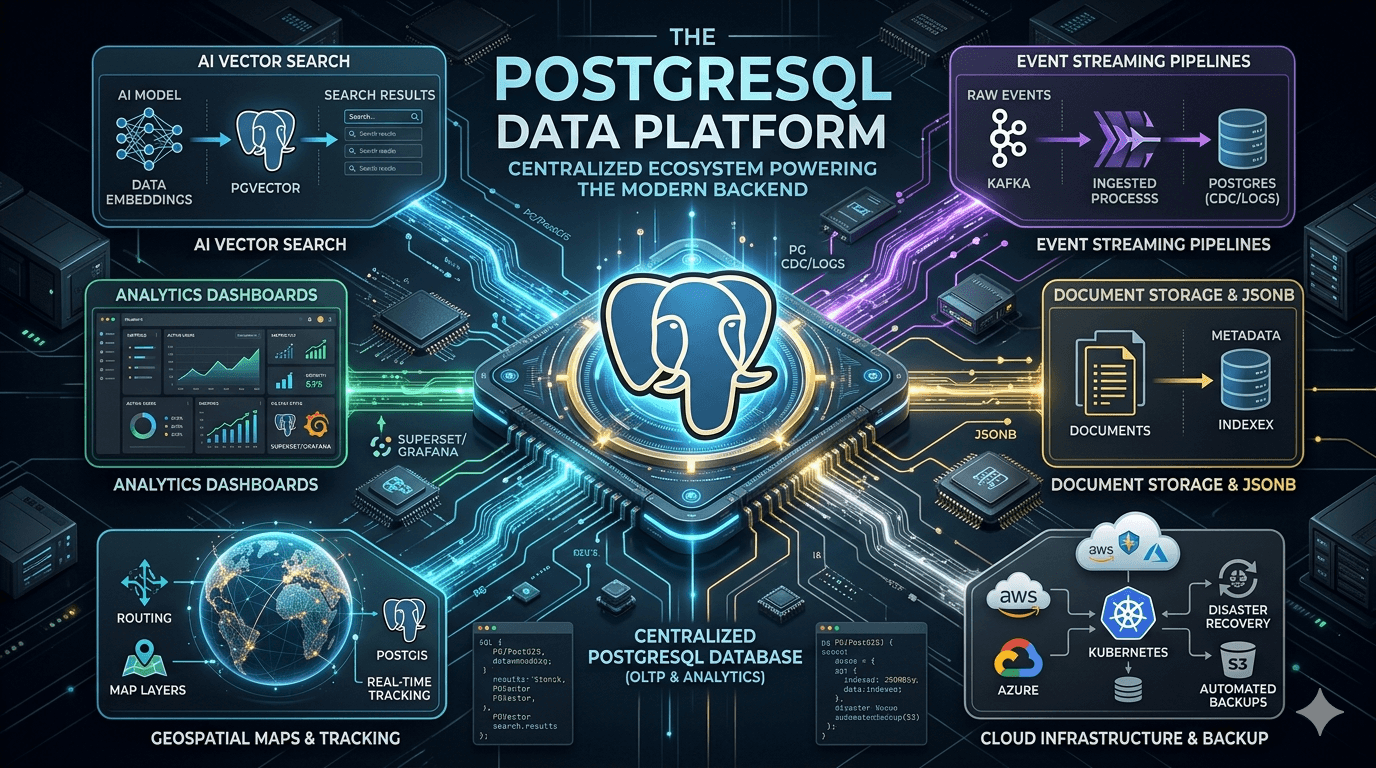
1. Introduction: The Database That Refused to Stay in Its Lane
For years, PostgreSQL was mainly viewed as a reliable relational database — the kind of technology you used for storing transactions, powering dashboards, or supporting enterprise applications.
That perception is now outdated.
Modern PostgreSQL has quietly evolved into something much bigger: a highly extensible data platform capable of handling workloads that previously required multiple specialized systems.
Today, engineering teams use PostgreSQL for:
- Traditional relational data
- Document-style storage
- Full-text search
- Event-driven architectures
- Geospatial applications
- Time-series workloads
- AI vector search
- Analytics pipelines
- Queue processing
This shift matters because infrastructure complexity has a cost.
Every additional service introduced into a system increases:
- Operational overhead
- Deployment complexity
- Security surface area
- Monitoring requirements
- Team cognitive load
- Failure modes
Senior engineers eventually realize that architecture is not about using the most technologies possible.
It is about introducing complexity only when the benefits clearly outweigh the operational cost.
PostgreSQL has become incredibly valuable because it allows teams to consolidate capabilities into a single, mature, battle-tested platform.
2. PostgreSQL Still Excels at the Fundamentals
Before discussing PostgreSQL's modern capabilities, it is important to understand why engineers trust it in the first place.
PostgreSQL remains one of the most reliable relational database systems ever built.
Some of its foundational strengths include:
i) ACID Compliance
PostgreSQL provides strong transactional guarantees:
- Atomicity
- Consistency
- Isolation
- Durability
This is critical for systems involving:
- Financial transactions
- Inventory systems
- Insurance platforms
- ERP systems
- Banking workflows
ii) MVCC (Multi-Version Concurrency Control)
PostgreSQL's MVCC architecture allows multiple users to read and write concurrently with minimal locking contention.
This dramatically improves performance under high concurrency while maintaining consistency.
iii) Advanced Query Engine
PostgreSQL supports:
- Complex joins
- Recursive CTEs
- Window functions
- Materialized views
- Partitioning
- Advanced indexing strategies
Many engineers underestimate just how powerful SQL becomes in PostgreSQL when used properly.
In many organizations, entire analytics pipelines can be simplified using well-designed SQL queries instead of introducing separate processing systems.
iv) Reliability Over Hype
One reason PostgreSQL continues to dominate is that it optimizes for correctness and durability rather than trendiness.
This aligns with an important engineering principle:
Boring technology at scale is often more valuable than exciting technology at scale.
The older systems become, the more reliability matters.
3. PostgreSQL as a Document Database
One of PostgreSQL's biggest evolutions came with JSON and JSONB support.
Traditionally, relational databases enforced rigid schemas while document databases like MongoDB prioritized flexibility.
PostgreSQL now provides a hybrid model.
i) JSONB Changes the Game
The JSONB data type allows PostgreSQL to store semi-structured data efficiently while still supporting indexing and querying.
Example:
CREATE TABLE products (
id SERIAL PRIMARY KEY,
metadata JSONB
);
INSERT INTO products (metadata)
VALUES (
'{
"brand": "Apple",
"storage": "256GB",
"specs": {
"ram": "8GB",
"chip": "M3"
}
}'
);You can query nested JSON directly:
SELECT *
FROM products
WHERE metadata->>'brand' = 'Apple';ii) Why This Matters
In many applications, not all data fits neatly into rigid relational tables.
Examples include:
- Dynamic product attributes
- User preferences
- Metadata
- Audit payloads
- API responses
- Event payloads
Previously, teams often introduced MongoDB purely for flexibility.
Now many startups simply use PostgreSQL for both relational and document-style workloads.
iii) The Important Trade-Off
This does not mean PostgreSQL completely replaces MongoDB.
MongoDB still has advantages in:
- Massive horizontal document scaling
- Schema-less rapid iteration
- Certain distributed workloads
However, PostgreSQL dramatically reduces the number of scenarios where introducing a second database is truly necessary.
4. PostgreSQL as a Search Engine
Search functionality is another area where PostgreSQL surprises many engineers.
Most developers assume that search automatically requires Elasticsearch or OpenSearch.
In reality, PostgreSQL's built-in full-text search capabilities are extremely capable for many applications.
i) Full-Text Search
Example:
SELECT title
FROM articles
WHERE to_tsvector(content)
@@ plainto_tsquery('postgresql');PostgreSQL supports:
- Tokenization
- Ranking
- Dictionaries
- Stemming
- Phrase matching
- Language-aware search
ii) Trigram Matching
PostgreSQL also supports fuzzy matching using pg_trgm.
This is useful for:
- Typo tolerance
- Autocomplete
- Search suggestions
- Similarity detection
Example:
SELECT *
FROM users
WHERE similarity(name, 'jon') > 0.4;iii) When PostgreSQL Search Is Enough
For many SaaS products, PostgreSQL search is more than sufficient.
Examples:
- Internal admin dashboards
- Blog platforms
- Knowledge bases
- E-commerce catalogs
- CRM systems
This eliminates the need to maintain:
- Separate search clusters
- Index synchronization pipelines
- Additional infrastructure costs
iv) When Dedicated Search Engines Still Win
Elasticsearch still dominates in scenarios involving:
- Massive distributed indexing
- Extremely large-scale log analysis
- Advanced search relevance tuning
- Multi-region search architectures
Again, the lesson is not that PostgreSQL replaces everything.
The lesson is that many teams introduce specialized infrastructure far earlier than necessary.
5. PostgreSQL as a Vector Database for AI Applications
The rise of AI applications introduced a new infrastructure trend: vector databases.
Companies rushed to adopt specialized tools for:
- Embedding storage
- Semantic search
- Retrieval-Augmented Generation (RAG)
- Recommendation systems
Then pgvector arrived.
i) What Is pgvector?
pgvector is a PostgreSQL extension that adds vector similarity search capabilities.
Example:
CREATE EXTENSION vector;
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
embedding vector(1536)
);Similarity search:
SELECT *
FROM documents
ORDER BY embedding <-> '[0.1, 0.2, 0.3]'
LIMIT 5;ii) Why This Is Important
This allows developers to build AI-powered systems directly inside PostgreSQL.
Examples include:
- AI chatbots
- Semantic document search
- Recommendation engines
- Knowledge retrieval systems
- AI-powered support systems
iii) Operational Simplicity Matters
Without pgvector, a team might need:
- PostgreSQL
- Pinecone
- Weaviate
- Qdrant
- Elasticsearch vector search
Each additional system increases complexity.
For many startups and internal tools, PostgreSQL plus pgvector is entirely sufficient.
iv) The Senior Engineering Perspective
The real architectural question becomes:
At what scale does introducing a dedicated vector database become justified?
That is a much more mature question than:
Which trendy vector database should we use?
6. PostgreSQL as a Queue and Event System
One of PostgreSQL's most underrated capabilities is supporting event-driven workflows.
Many systems introduce Redis, RabbitMQ, or Kafka extremely early.
Sometimes that is necessary.
Sometimes it is not.
i) LISTEN and NOTIFY
PostgreSQL includes built-in pub/sub capabilities:
NOTIFY order_created, 'Order #1024 created';Applications can subscribe using LISTEN.
This works surprisingly well for lightweight event systems.
ii) SKIP LOCKED for Queue Processing
PostgreSQL can also power job queues.
SELECT *
FROM jobs
WHERE status = 'pending'
FOR UPDATE SKIP LOCKED
LIMIT 1;This allows multiple workers to process jobs concurrently without collisions.
iii) The Outbox Pattern
Many senior backend systems use PostgreSQL as the source of truth for event publishing.
Instead of directly publishing events from application code:
- Write business transaction
- Write outbox event in same transaction
- Separate worker publishes events
This guarantees consistency.
iv) Logical Replication and CDC
PostgreSQL's logical replication capabilities enable Change Data Capture (CDC).
This allows systems to stream database changes into:
- Kafka
- Analytics systems
- Search indexes
- Data warehouses
Tools like Debezium heavily rely on this model.
At this point, PostgreSQL stops behaving like a simple database and starts behaving like infrastructure middleware.
7. Extensions Are PostgreSQL's Real Superpower
The biggest reason PostgreSQL continues expanding into new domains is its extension ecosystem.
Extensions allow PostgreSQL to evolve without bloating the core database.
This architectural decision was brilliant.
i) Popular PostgreSQL Extensions
a) PostGIS
Adds geospatial capabilities.
Used for:
- Maps
- Ride-hailing apps
- Logistics systems
- Delivery tracking
- Spatial analytics
b) TimescaleDB
Optimizes PostgreSQL for time-series workloads.
Useful for:
- IoT systems
- Monitoring platforms
- Financial metrics
- Sensor data
c) pgvector
Adds AI vector similarity search.
d) Citus
Enables distributed PostgreSQL clustering.
e) pg_trgm
Provides fuzzy text matching.
ii) Why Extensions Matter
Extensions transform PostgreSQL into a platform instead of a single-purpose product.
This is similar to how:
- Linux evolved through packages
- Kubernetes evolved through operators
- VS Code evolved through plugins
The extensibility model is one of PostgreSQL's greatest long-term strategic advantages.
8. Where PostgreSQL Should NOT Be Used
A common mistake among engineers is turning enthusiasm into dogma.
PostgreSQL is extremely capable, but it is not always the correct choice.
i) Ultra-Large Distributed Search
At internet-scale search workloads, Elasticsearch and OpenSearch remain superior.
ii) Extremely High Throughput Streaming
Kafka still dominates large-scale event streaming.
iii) Specialized OLAP Systems
Systems like ClickHouse and Snowflake outperform PostgreSQL for massive analytical workloads.
iv) Massive Write-Heavy Time-Series Systems
Dedicated time-series databases may outperform PostgreSQL at extreme ingestion rates.
v) Why This Section Matters
Good engineering is not about proving one technology is universally superior.
It is about understanding trade-offs.
Technology selection should be driven by:
- Scale
- Team expertise
- Operational complexity
- Cost
- Performance requirements
- Long-term maintainability
PostgreSQL is powerful because it delays the need for specialization.
That distinction matters.
9. Why PostgreSQL Keeps Winning
PostgreSQL's dominance is not accidental.
It succeeds because it aligns with what mature engineering organizations eventually optimize for:
- Reliability
- Operational simplicity
- Extensibility
- Strong consistency
- Cost efficiency
- Ecosystem maturity
- Long-term maintainability
i) Cloud Providers Fully Embrace PostgreSQL
Every major cloud provider heavily supports PostgreSQL:
- AWS RDS and Aurora PostgreSQL
- Google Cloud SQL
- Azure Database for PostgreSQL
- Supabase
- Neon
- Railway
- Render
This ecosystem maturity significantly reduces adoption risk.
ii) PostgreSQL Ages Well
Many technologies become harder to maintain as systems grow.
PostgreSQL tends to become more valuable over time because:
- The ecosystem matures
- Tooling improves
- Extensions evolve
- Community knowledge expands
This is one reason many senior engineers repeatedly return to PostgreSQL after experimenting with newer systems.
They eventually realize:
Infrastructure simplicity compounds positively over time.
10. Conclusion: The Real Question Is About Complexity
PostgreSQL is no longer just a relational database.
It has evolved into a flexible backend platform capable of supporting a remarkable range of workloads.
The most important lesson, however, is not about PostgreSQL itself.
It is about engineering judgment.
Modern software architecture is often less about adding technologies and more about resisting unnecessary complexity.
Every additional service introduced into a system creates:
- More deployments
- More monitoring
- More debugging
- More networking
- More security concerns
- More operational overhead
PostgreSQL has become incredibly valuable because it allows teams to consolidate capabilities without immediately sacrificing reliability.
Eventually, scale and specialization may justify introducing dedicated systems.
But many teams discover that PostgreSQL can take them much further than they originally imagined.
The question is no longer:
Can PostgreSQL do this?
The real question is:
Is adding another piece of infrastructure truly worth it?
Share this article
If you found this post helpful, feel free to share it with your network!
About the Author
